수업을 마치고 좀 더 정리해서 올리려고 하다보니
자꾸 게시물이 밀리고 있다.
수업이 끝나는 동시에 정리도 완료하는 걸 목표로 해야겠다.
이번주부터 투잡 느낌으로 너무나 바쁘다..
오전 8시 반 ~ 오후 6시까지는 공빅(공공빅데이터 청년인턴십)
오후 6시부터 밤 10시,11시까지는 론칭 예정인 서비스 개발을 기획 및 진행 중에 있다.
게다가 이번주에는 면접까지 잡혀서 이렇게 되면 뺄 수 있는 물리적인 시간이 잠자는 시간밖에 없다.
어쨋든 이번 한주도 홧팅이다,,
1.1. 파이썬 크롤링 (웹페이지 크롤링)

웹 크롤링 - 웹페이지에서 우리가 필요한 데이터를 추출해오는 것
웹 스크래핑 - 신문스크랩하듯 우리가 원하는 부분을 발췌하는 것 ≫ 웹 크롤링을 통해 추출된 데이터 중에서 우리에게 꼭 필요한 데이터만 선별해서 저장하는 것
웹 페이지 추출
- 웹 페이지 추출 시, HTTP 헤더와 HTML meta태그를 기반으로 인코딩 방식을 판별 필요
- (파이썬 내장) 표준 라이브러리 urllib.request 모듈을 사용하여 웹페이지 추출
- urllib.request에 포함돼 있는 urlopen()함수에 url을 지정하면 웹페이지 추출 가능
- HTTP 헤더를 변경 불가, Basic 인증 사용을 위한 복잡한 처리 필요
- HTTP헤더 변경 및 Basic인증을 위해 urllib 대신 Requests 모듈 사용 필요
ㄴ 실습(1). 2.4.1.1.urllib.ipynb실습
from urllib.request import urlopen
f = urlopen('http://hanbit.co.kr')
# urlopen() 함수는 HTTPResponse 자료형의 객체를 반환
# 파일 객체이므로 open() 함수로 반환되는 파일 객체처럼 핸들링
type(f)
# read() 메서드로 HTTP 응답 본문(bytes 자료형)을 추출
# HTTP 연결은 자동으로 close 되므로 별도의 close() 함수를 호출
f.read()
f.status #200
f.getheader('Content-Type') #'text/html; charset=UTF-8'
문자코드 다루기
- HTTPResponse.read() 메서드로 추출할 수 있는 HTTPResponse 본문은 bytes 자료형
- 문자열(str자료형)으로 다루려면 문자 코드를 지정해서 디코딩 필요
- 최근에는 HTML5 기본 인코딩 방식인 utf-8 전제로 디코딩 가능
- 한국어 사이트를 크롤링 시 여러가지 인코딩이 혼합되어 있을 수 있으므로 HTTP 헤더를 참조해서 적절한 인코딩 방식으로 디코딩 필요
HTTP 헤더에서 인코딩 방식 추출

ㄴ 실습. 2.4.2.1.urlopen_encoding.ipynb
import sys
from urllib.request import urlopen
f = urlopen('http://www.hanbit.co.kr/store/books/full_book_list.html')
# HTTP 헤더를 기반으로 인코딩 방식을 추출(명시돼 있지 않을 경우 utf-8을 사용)
encoding = f.info().get_content_charset(failobj="utf-8")
# 인코딩 방식을 표준 오류에 출력
print('encoding:', encoding)
# 추출한 인코딩 방식으로 디코딩
text = f.read().decode(encoding)
# 웹 페이지의 내용을 표준 출력에 출력
print(text)
with open('dp.html', 'w', encoding=encoding) as wf:
wf.write(text)
ㄴ 실습. 2.4.2.2.urlopen_meta.ipynb
UTF-8로 디코딩 수행 후, 사람이 인식할 수 있는 한글형태로 출력
import re
import sys
from urllib.request import urlopen
f = urlopen('http://www.hanbit.co.kr/store/books/full_book_list.html')
# bytes 자료형의 응답 본문을 일단 변수에 저장
bytes_content = f.read()
# charset은 HTML의 앞부분에 적혀 있는 경우가 많으므로
# 응답 본문의 앞부분 1024바이트를 ASCII 문자로 디코딩
# ASCII 범위 이위의 문자는 U+FFFD(REPLACEMENT CHARACTER)로 변환되어 예외가 발생하지 않음
scanned_text = bytes_content[:1024].decode('ascii', errors='replace')
# 디코딩한 문자열에서 정규 표현식으로 charset 값을 추출
match = re.search(r'charset=["\']?([\w-]+)', scanned_text)
match.group(1)
if match:
encoding = match.group(1)
else:
# charset이 명시돼 있지 않으면 UTF-8을 사용
encoding = 'utf-8'
# 추출한 인코딩을 표준 오류에 출력
print('encoding:', encoding, file=sys.stderr)
# 추출한 인코딩으로 다시 디코딩
text = bytes_content.decode(encoding)
# 응답 본문을 표준 출력에 출력
print(text)
1-2. 정규식을 이용한 스크래핑
웹페이지에서 데이터 추출

정규 표현식을 이용한 스크래핑

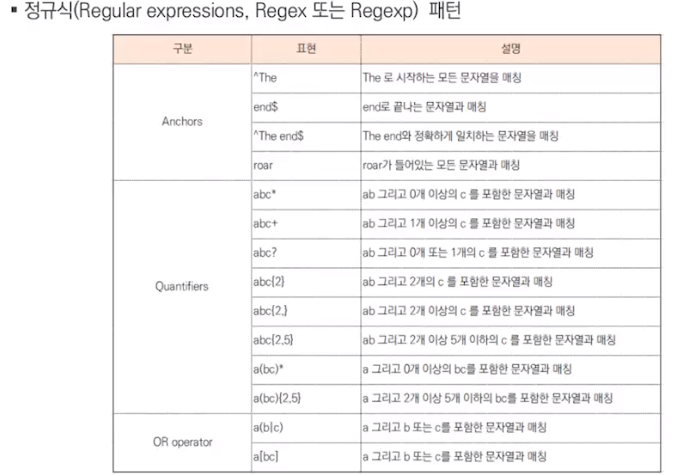

ㄴ 실습(2). 2.5.1.2.scrape_re.ipynb
import re
from html import unescape
# 이전 절에서 다운로드한 파일을 열고 html이라는 변수에 저장
with open('dp.html', encoding='utf-8') as f:
html = f.read()
# re.findall() 메서드를 통해 도서 하나에 해당하는 HTML을 추출
for partial_html in re.findall(r'<td class="left"><a.*?</td>', html, re.DOTALL):
# 도서의 URL을 추출
url = re.search(r'<a href="(.*?)">', partial_html).group(1)
url = 'http://www.hanbit.co.kr' + url
# 태그를 제거해서 도서의 제목을 추출
title = re.sub(r'<.*?>', '', partial_html)
title = unescape(title)
print('url:', url)
print('title:', title)
print('---')
1-3. XML 스크래핑
XML을 이용한 스크래핑

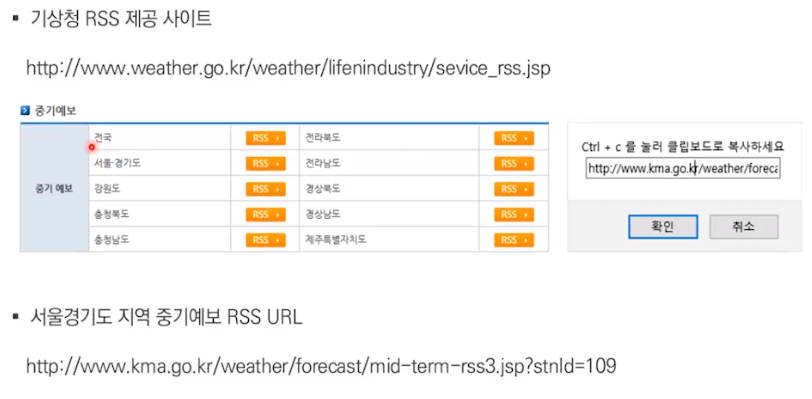
ㄴ 실습(3). 2.5.2.1.python_rss.ipynb
# ElementTree 모듈을 로드
from xml.etree import ElementTree
# parse() 함수로 파일을 읽고 ElementTree 객체를 생성
tree = ElementTree.parse('rss.xml')
# getroot() 메서드로 XML의 루트 element를 추출
root = tree.getroot()
import pandas as pd
데이터프레임_리스트 = []
for item in root.findall('channel/item/description/body/location/data'):
# find() 메서드로 element 탐색, text 속성으로 값을 추출
tm_ef = item.find('tmEf').text
tmn = item.find('tmn').text
tmx = item.find('tmx').text
wf = item.find('wf').text
데이터프레임 = pd.DataFrame({
'일시':[tm_ef],
'최저기온':[tmn],
'최고기온':[tmx],
'날씨':[wf],
})
데이터프레임_리스트.append(데이터프레임)
날씨정보 = pd.concat(데이터프레임_리스트)
날씨정보
type(날씨정보)
날씨정보.to_csv('날씨정보.csv')
엑셀 = pd.ExcelWriter('날씨정보.xlsx')
날씨정보.to_excel(엑셀, '.', index=False )
엑셀.save()
날씨정보.reset_index(drop=True, inplace=True)
날씨정보.to_json('날씨정보.json')
import sqlite3
from pandas.io import sql
import os
with sqlite3.connect(os.path.join('.','sqliteDB')) as con: # sqlite DB 파일이 존재하지 않는 경우 파일생성
try:
날씨정보.to_sql(name = 'WEATHER_INFO', con = con, index = False, if_exists='append')
#if_exists : {'fail', 'replace', 'append'} default : fail
except Exception as e:
print(str(e))
query = 'SELECT * FROM WEATHER_INFO'
데이터프레임1 = pd.read_sql(query, con = con)
엑셀 = pd.ExcelWriter('날씨정보2.xlsx')
데이터프레임1.to_excel(엑셀, '.', index=False )
엑셀.save()
df = pd.read_excel('날씨정보2.xlsx')
1-4. 스크래핑 데이터 저장
CSV 형식으로 저장

ㄴ 실습(4). 2.6.1.1.save_csv.ipynb
ㄴ 실습(4). 2.6.1.2.save_csv_dict.ipynb
ㄴ 실습(4). 2.6.1.3.encoding_check.ipynb
JSON 형식으로 저장

ㄴ 실습(4). 2.6.2.1.save_json.ipynb
SQLite3 DBMS로 저장

ㄴ 실습(4). 2.6.3.1.save_sqlite3.ipynb
1-5. 고급 라이브러리를 이용한 스크래핑
파이썬 스크래핑 프로세스
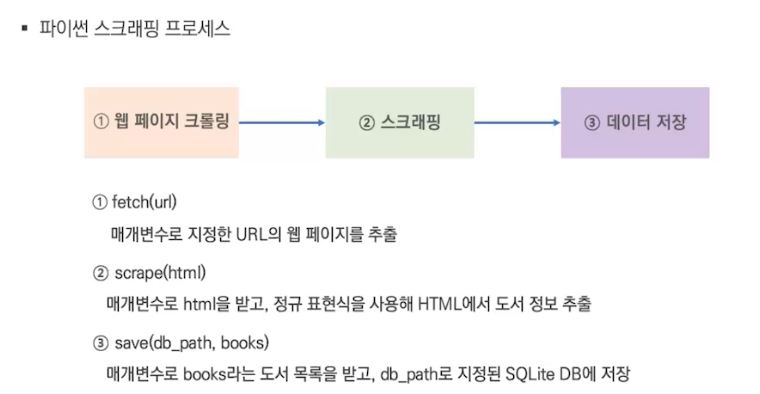
ㄴ 실습(5). 2.7.1.1.python_scraper.ipynb
HTML 스크래핑

* 스크래핑을 위한 라이브러리는 모두 XPath와 CSS Selector를 이용하여 스크래핑 수행
Lxml을 이용한 스크래핑

ㄴ 실습(5). 3.3.2.1.scrape_by_lxml.ipynb
Beautiful Soup을 이용한 스크래핑

ㄴ 실습(5). 3.3.2.2.scrape_by_bs4.ipynb
1-6. URL과 퍼머링크
URL 기초 지식
URL이란? 웹상에 존재하는 동적, 정적 자원들의 위치 locator

① http 프로토콜
웹(환경)은 http라는 약속을 통해 서버와 클라이언트 간에 (요청하는 측: 클라이언트 / 요청을 받는 측: 서버) 요청(request)과 응답(response)을 통해 대화
※ 프로토콜이란? 클라이언트와 서버 간 요청과 응답을 주고받기 위한 약속.
※ https 프로토콜? 일반적인 http의 경우 암호화되어있지 않기 때문에 암호화된 상태로 정보를 주고받음. 안정성, 보안성 제공
② authority : 도메인 명
※ 도메인? 사람이 인식할 수 있는 논리적인 주소
※ ip주소? 컴퓨터가 인식할 수 있는 논리적인 주소
③ path : 호스트 내부 리소스 경로
main 서버쪽에 있는 디렉토리
index 파일 or 디렉토리 or 자원
④ query : 물음표 뒷 부분. 부가적으로 전달되어야 하는 리소스 정보.
⑤ flagment : # 뒷 부분. html문서의 특정 위치를 지정할 때 사용
절대 URL과 상대 URL

절대 경로 : 맨 위의 최상위 디렉토리인 root디렉토리를 기준으로 경로 지정
상대 경로 : 현재 디렉토리를 기준으로 해서 경로 지정
상대 URL을 절대 URL로 변환
urljoin()함수 사용 - urllib.parse 모듈에 포함되어 있음

퍼머링크와 링크 구조 패턴
퍼머링크 (Permalink) 란?

목록/상세 패턴

퍼머링크는 일반적으로 목록페이지에서 상세페이지에 링크를 걸기 위해서 사용됨.
≫ 목록페이지가 가지고 있는 링크들도 같이 스크래핑해서 추출된 url 혹은 퍼머링크를 다시 서버측에 요청해서 상세페이지를 가져오는 방식으로 사용.
'자기계발 > 대외활동' 카테고리의 다른 글
| [공공빅데이터 청년인턴십] [day11 - 07.19(월)] Q-GIS 공간분석 실습기초(1) (0) | 2021.07.19 |
|---|---|
| [공공빅데이터 청년인턴십] [day7 - 07.13(화)] Python으로 배우는 외부데이터 수집과 정제(2) (0) | 2021.07.13 |
| [공공빅데이터 청년인턴십] [day3 - 07.07(수)] Python 프로그래밍 이해(2) (0) | 2021.07.07 |
| [공공빅데이터 청년인턴십] [day2 - 07.06(화)] 데이터에 대한 이해와 정형데이터 다루기(모델링) (0) | 2021.07.06 |
| [공공빅데이터 청년인턴십] 사전교육 (5/31~) (0) | 2021.06.04 |



